Unlocking Interpretability in Signed Graph Neural Networks
Introduction
Understanding the workings of graph neural networks (GNNs) is crucial. My research addressed interpretability challenges in signed graphs by designing a self-explainable graph transformer model (SE-SGformer).
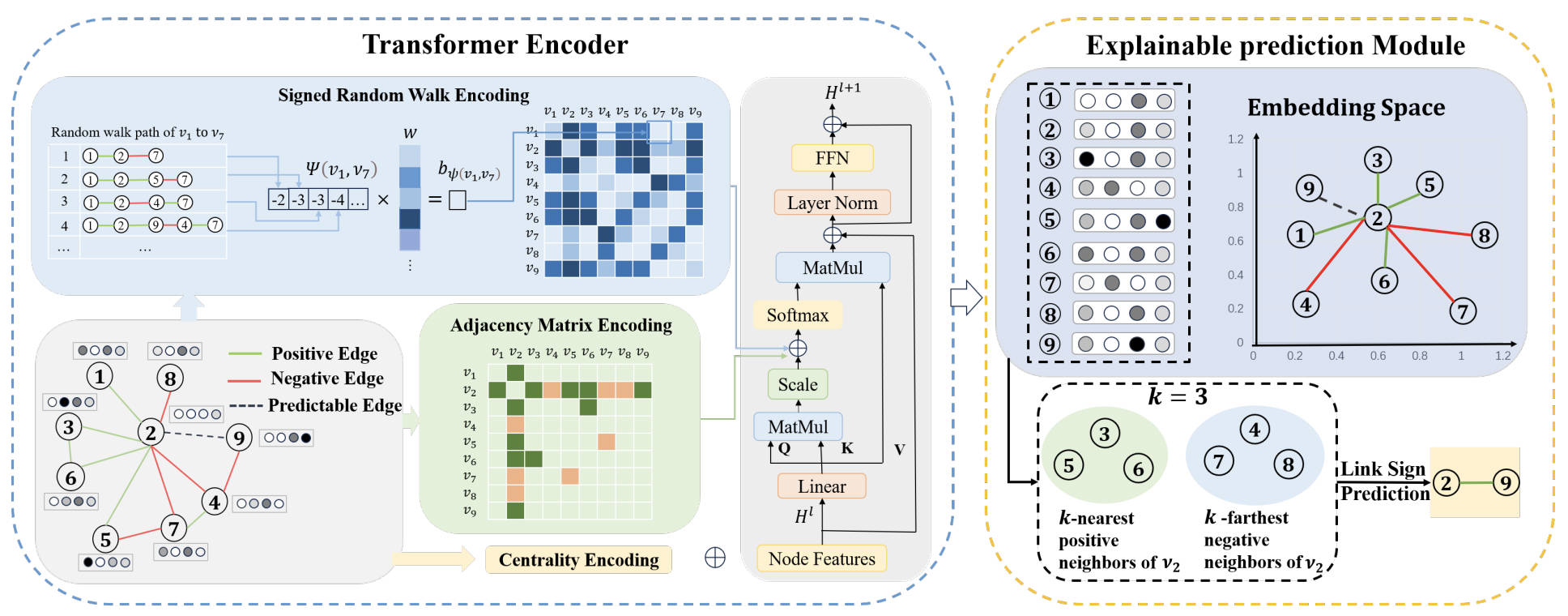
Key Contributions
- Developed position encoding based on signed random walks.
- Achieved 2.2% improvement in prediction accuracy and a 73.1% increase in interpretability.
- Refined experiments and model designs on real-world datasets.
Impact
This work pushes the boundaries of explainable AI in graph-based tasks.