SSEFormer: A Sign-Sensitive Transformer with Semantic Fusion for Link Sign Prediction
A signed graph Transformer that fuses BERT-derived review semantics with rating signals and explicitly compensates for the softmax bias against negative edges.
Abstract
Signed graphs are widely used in social networks, recommendation, and trust modeling, where positive and negative relationships coexist. Most existing Signed GNNs build the graph topology from raw user ratings, ignoring the subjectivity of feedback and the semantic conflicts between ratings and review text. Furthermore, when Transformers are applied to signed graphs, softmax attention is provably biased toward positive neighbors, suppressing the contribution of informative negative edges. We propose SSEFormer, a sign-sensitive Transformer that (i) reconstructs the signed adjacency by fusing rating-based and BERT-based semantic labels, and (ii) introduces a sign-aware mask that dynamically rebalances attention across edge polarities and structural distances. SSEFormer outperforms strong signed-graph baselines by up to 17.0% AUC on Amazon-Music.
Motivation & Challenges
Two issues motivate our design:
- Challenge 1 — Constructing the signed graph. Numerical ratings are subjective and frequently inconsistent with review semantics (e.g., a 5-star score paired with a sarcastic review). Building the signed adjacency from ratings alone propagates this noise into downstream learning.
- Challenge 2 — Sign-aware Transformer modeling. Standard Transformers apply indiscriminate global attention. We prove (Theorem 2 in the paper) that under softmax attention, even when the number of positive and negative neighbors is balanced, negative edges receive exponentially less attention — a structural failure that increases the Rademacher complexity bound and degrades generalization.
Methodology
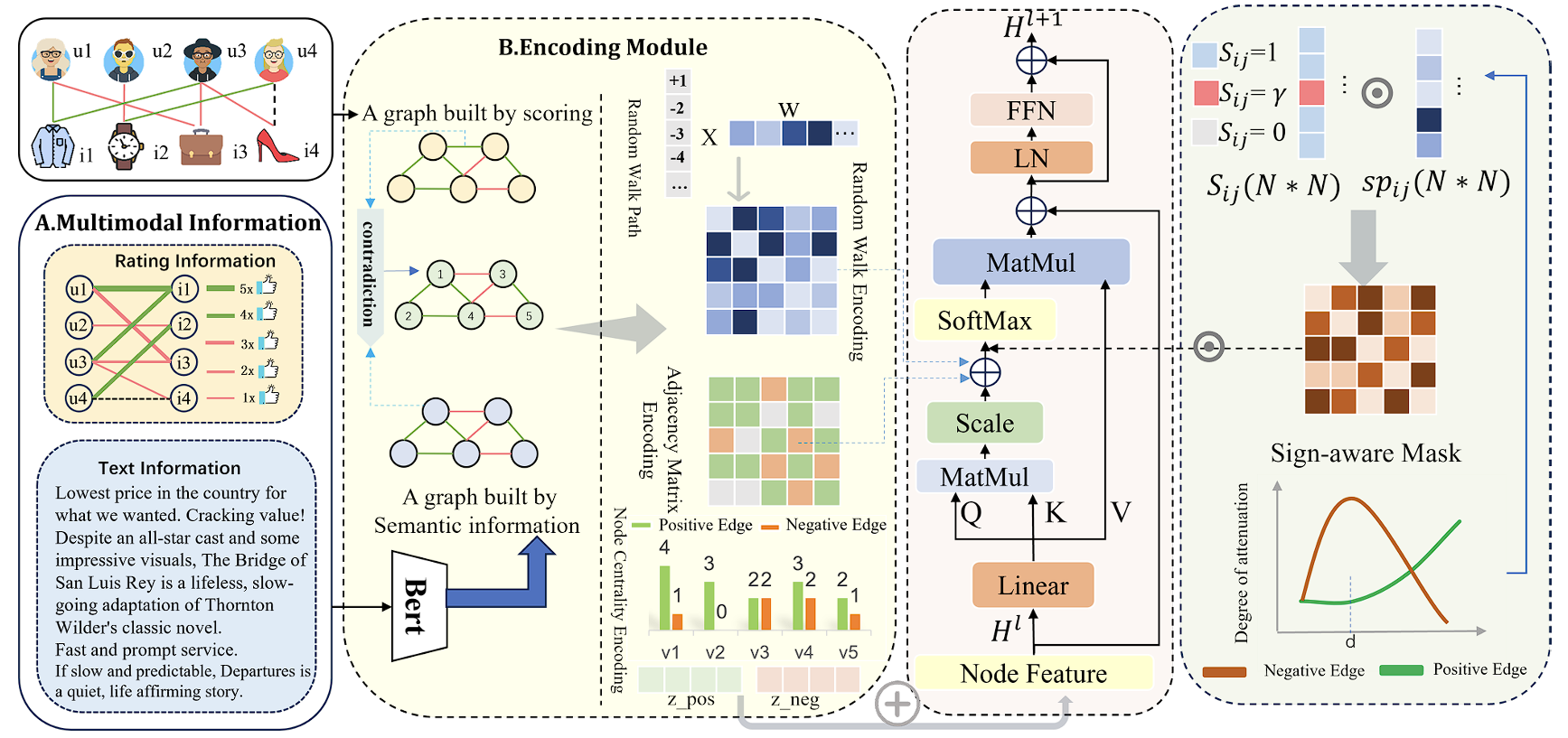
SSEFormer is composed of four modules: a Multi-source Fusion (MSF) module, an Encoding module, a Sign-aware Mask module, and a Transformer layer.
- MSF Module — semantic-aware adjacency. A pre-trained BERT generates a semantic edge label yuvtext from review text. When the rating-based label yuvscore conflicts with yuvtext (i.e., yscore · ytext ≤ 0), the semantic label takes precedence; otherwise the rating label is kept. This filters subjective rating noise at the source.
- Encoding Module. Three structural encodings inject sign-aware bias into self-attention: (i) signed centrality encoding from per-node positive / negative degrees, (ii) signed adjacency encoding as an attention bias term, and (iii) signed random walk encoding via signed random walk with restart (SRWR), which Theorem 1 proves to be strictly more expressive than shortest-path encoding.
- Sign-aware Mask. The mask Mij = sij · sijp combines a sign-distance term — which suppresses ambiguous mid-range negative edges and enhances long-range structural conflicts — with an exponential structural decay sijp = exp(−λ dij). The negative-edge response f(dij) is convex in distance, with parameters β, dth, γ, α, δ controlling lower bound, threshold, smoothness, steepness, and deviation respectively.
- Transformer Layer. The mask is applied multiplicatively to the masked attention scores (QK⊤ + Â + bψ(i,j)) · Mij before softmax, after which standard residual + LayerNorm + FFN blocks are stacked. Training combines a 3-class NLL loss (positive / negative / null edges) with structure-aware triplet losses.
Theoretical analysis (Theorems 2–3) further shows that without explicit compensation, suppressing negative-edge attention increases the upper bound of the weighted Rademacher complexity, providing a generalization-theoretic justification for the sign-aware mask.
Key Results
We evaluate SSEFormer on four real-world datasets that pair ratings with review text — Amazon-Music, DMSC (Douban Movies), Trustpilot, and Rotten Tomatoes Movies — against unsigned (GCN, GAT) and signed (SGCN, SNEA, SGCL, SIGformer) baselines.
State-of-the-Art on Amazon-Music
SSEFormer reaches AUC 78.14%, Acc 79.15%, F1 85.32% — a +17.0% AUC gain over the strongest baseline (SIGformer, 61.17%).
Large Gains on DMSC and Trustpilot
AUC reaches 94.09% on DMSC and 87.43% on Trustpilot, with absolute Acc improvements of 26+ percentage points over GCN/GAT baselines.
Robustness Under Semantic Noise
On Rotten Tomatoes — where sarcasm and mixed sentiment make all baselines collapse to near-random (~50% AUC) — SSEFormer still attains 84.86% AUC, evidencing that semantic fusion captures subtle signed semantics where rating-only models fail.
Negative-Edge Discrimination
Embedding-distance analysis shows the sign-aware mask amplifies the gap between positive- and negative-edge node distances by 93%–300% across datasets, directly translating into 3–5 pp gains in negative-edge prediction accuracy.
Conclusion
SSEFormer integrates structural and semantic supervision into a single signed-graph Transformer and explicitly compensates for the softmax bias against negative edges. The combination yields consistent state-of-the-art performance on link sign prediction across four heterogeneous datasets, while the theoretical analysis grounds the sign-aware mask in a generalization-error argument. We are extending the framework to multi-modal signed graphs (e.g., biological interaction networks with textual annotations).
Citation
This paper is currently under review. Please cite the preprint:
@article{zhang2025sseformer,
title = {SSEFormer: A Sign-Sensitive Transformer with Semantic Fusion for Link Sign Prediction},
author = {Zhang, Tianning and Li, Lu and Liu, Jiale and Zhu, Xiaofeng and Wang, Maojun and Zhang, Zeyu},
note = {Preprint submitted to Elsevier, under review},
year = {2025}
}