Self-Explainable Graph Transformer for Link Sign Prediction (SE-SGformer)
A self-explainable signed graph Transformer that delivers state-of-the-art link sign prediction together with neighbor-level explanations. Published at AAAI 2025.
Abstract
Signed Graph Neural Networks (SGNNs) are widely used to model coexisting positive and negative relationships in domains such as social networks, recommendation, and trust prediction. Existing SGNNs, however, suffer from poor explainability, which limits their deployment in critical scenarios where the rationale behind a predicted link sign matters. We propose SE-SGformer, the first self-explainable signed graph Transformer for link sign prediction. The model couples a Transformer encoder equipped with a novel signed random walk encoding with a neighbor-based explainable predictor that returns the K-nearest positive and K-farthest negative neighbors as the explanation alongside each prediction.
Motivation & Challenges
Post-hoc explainers (e.g., GNNExplainer, PGExplainer) are decoupled from the model and can produce explanations that do not faithfully reflect the model's reasoning. Existing self-explainable GNNs (e.g., SE-GNN, ProtGNN) are designed for unsigned graphs and node / graph classification, and do not transfer to link sign prediction. Building a self-explainable model for signed graphs raises two challenges:
- Challenge 1 — Encoding. Improving node-representation quality in signed graphs is hard: SGNNs are typically capped at three layers to avoid over-smoothing, restricting multi-hop reach, and GCN-style aggregation cannot resolve unbalanced cycles.
- Challenge 2 — Explanation. Many real-world signed graphs are extremely sparse in negative neighbors. On Bitcoin-Alpha, for instance, more than 80% of nodes have no negative neighbor at all, making neighbor-based explanations infeasible without an explicit mechanism to recover them.
Methodology
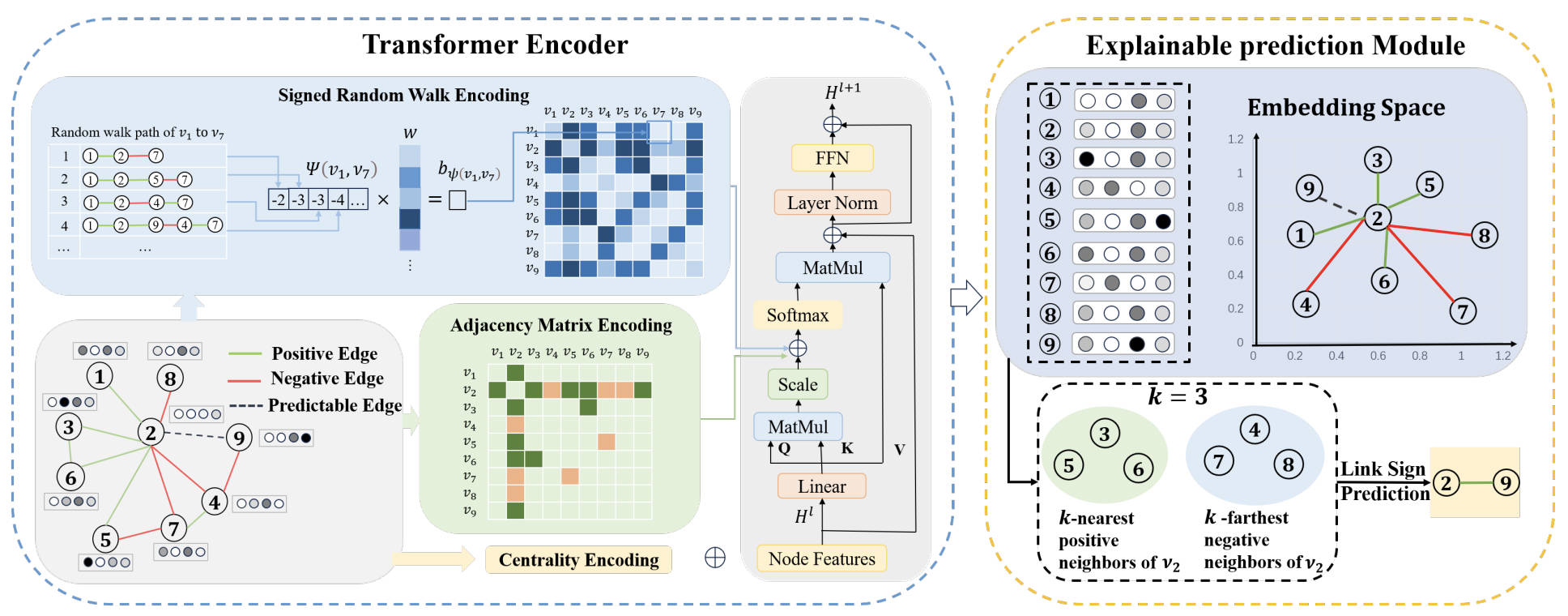
SE-SGformer consists of two coupled modules: an Encoding Module that produces signed-aware node embeddings via a Transformer with three structural encodings, and an Explainable Prediction Module that decides edge signs from neighbor similarity, returning the supporting neighbors as the explanation.
- Centrality encoding. Two learnable vectors are added to each node based on its positive and negative degrees: hi(0) = xi + c−deg−(vi) + c+deg+(vi), capturing sign-aware node importance.
- Adjacency-matrix encoding. The normalized signed adjacency matrix is added as a bias term inside self-attention, injecting one-hop sign information directly into the attention scores.
- Signed random walk encoding (SRWE). To capture multi-hop relations beyond a single shortest path, we run multiple non-backtracking signed random walks and aggregate path-distance signals as a learnable bias bψ(vi, vj). Theorem 1 shows that, with a sufficient number of walks, SRWE is strictly more expressive than shortest-path encoding for signed graphs; Theorem 2 further shows that the resulting Transformer is more expressive than SGCN.
- Explainable prediction via K-nearest / K-farthest neighbors. For an unknown edge (vi, vj), we identify vi's K-nearest positive and K-farthest negative neighbors in the embedding space; the predicted sign — and its explanation — follows from which set vj is closer to. To address the negative-neighbor sparsity (Challenge 2), candidate negative neighbors are augmented using a Signed Random Walk with Restart (SRWR) diffusion matrix.
Key Results
We evaluate SE-SGformer on eight real-world signed graphs (Bitcoin-Alpha, Bitcoin-OTC, Slashdot, Epinions, etc.) under the standard 80/20 link-sign-prediction protocol. We compare against signed (SGCN, SGCL, SNEA, SiGAT) and unsigned (GCN, GAT) baselines, and against post-hoc explainers (GNNExplainer, PGExplainer) on explanation quality.
Prediction Accuracy
Up to +2.2% accuracy over the strongest signed-GNN baseline on link sign prediction in the best-case dataset, while remaining competitive across all eight benchmarks.
Explanation Quality
Up to +73.1% explainability accuracy over post-hoc baselines (best case), with explanations that are intrinsically faithful rather than reverse-engineered from a trained black box.
Theoretical Grounding
Two formal expressiveness results show that signed random walk encoding strictly subsumes shortest-path encoding, and that our Transformer is strictly more expressive than SGCN under sufficient walk length.
Recovering Negative Neighbors
The SRWR-based augmentation supplies meaningful negative neighbors even on graphs where 80%+ of nodes have none observed, making neighbor-based explanations practical at scale.
Conclusion
SE-SGformer is, to the best of our knowledge, the first self-explainable model designed specifically for link sign prediction on signed graphs. By replacing the neural decoder with a neighbor-based explainable predictor and equipping the Transformer with sign-aware random walk encoding, the framework demonstrates that strong predictive accuracy and faithful, human-readable explanations are jointly achievable for signed graph learning.
Code is available at github.com/liule66/SE-SGformer.
Citation
If you find this work useful, please cite:
@inproceedings{li2025self,
title = {Self-Explainable Graph Transformer for Link Sign Prediction},
author = {Li, Lu and Liu, Jiale and Ji, Xingyu and Wang, Maojun and Zhang, Zeyu},
booktitle = {Proceedings of the AAAI Conference on Artificial Intelligence},
volume = {39:11},
pages = {12084--12092},
year = {2025}
}